Корреляция
Содержание:
- Пример корреляции Спирмена
- Распространенные заблуждения
- Понятие корреляции
- Анализ временной задержки
- Памятка
- Корреляция и диверсификация
- Коэффициент линейной корреляции
- Положительное соотношение
- Пример применения метода корреляционного анализа
- 3) уравнение линейной регрессии на
- Терминология в обработке изображений
- Коэффициенты ранговой корреляции
- Примеры
Пример корреляции Спирмена
Необходимо установить наличие корреляционной связи между рабочим стажем и показателем травматизма при наличии следующих данных:
| Рабочий стаж в годах | Травматизм на 100 работающих |
| до 1 года | 24 |
| 1-2 | 16 |
| 3-4 | 12 |
| 5-6 | 12 |
| 7 и более | 6 |
Наиболее подходящим методом анализа является ранговый метод, т.к. один из признаков представлен в виде открытых вариантов: рабочий стаж до 1 года и рабочий стаж 7 и более лет.
Решение задачи начинается с ранжирования данных, которые сводятся в рабочую таблицу и могут быть выполнены вручную, т.к. их объем не велик:
| Рабочий стаж | Число травм | Порядковые номера | (ранги) | Разность рангов | Квадрат разности рангов |
| d(х-у) | |||||
| до 1 года | 24 | 1 | 5 | -4 | 16 |
| 1-2 | 16 | 2 | 4 | -2 | 4 |
| 3-4 | 12 | 3 | 2,5 | +0,5 | 0,25 |
| 5-6 | 12 | 4 | 2,5 | +1,5 | 2,5 |
| 7 и более | 6 | 5 | 1 | +4 | 16 |
| Σ d2 = 38,5 |
Появление дробных рангов в колонке связано с тем, что в случае появления вариант одинаковых по величине находится среднее арифметическое значение ранга. В данном примере показатель травматизма 12 встречается дважды и ему присваиваются ранги 2 и 3, находим среднее арифметическое этих рангов (2+3)/2= 2,5 и помещаем это значение в рабочую таблицу для 2 показателей. Выполнив подстановку полученных значений в рабочую формулу и произведя несложные расчёты получаем коэффициент Спирмена равный -0,92
Отрицательное значение коэффициента свидетельствует о наличии обратной связи между признаками и позволяет утверждать, что небольшой стаж работы сопровождается большим числом травм. Причем, сила связи этих показателей достаточно большая. Следующим этапом расчётов является определение достоверности полученного коэффициента: • рассчитывается его ошибка и критерий Стьюдента
Распространенные заблуждения
Корреляция и причинно-следственная связь
Традиционное изречение, что « корреляция не подразумевает причинно-следственную связь », означает, что корреляция не может использоваться сама по себе для вывода причинной связи между переменными. Это изречение не должно означать, что корреляции не могут указывать на потенциальное существование причинно-следственных связей. Однако причины, лежащие в основе корреляции, если таковые имеются, могут быть косвенными и неизвестными, а высокие корреляции также пересекаются с отношениями идентичности ( тавтологиями ), где не существует причинных процессов. Следовательно, корреляция между двумя переменными не является достаточным условием для установления причинно-следственной связи (в любом направлении).
Корреляция между возрастом и ростом у детей довольно прозрачна с точки зрения причинно-следственной связи, но корреляция между настроением и здоровьем людей менее очевидна. Приводит ли улучшение настроения к улучшению здоровья, или хорошее здоровье приводит к хорошему настроению, или и то, и другое? Или в основе обоих лежит какой-то другой фактор? Другими словами, корреляция может рассматриваться как свидетельство возможной причинной связи, но не может указывать на то, какой может быть причинная связь, если таковая имеется.
Простые линейные корреляции

Четыре набора данных с одинаковой корреляцией 0,816
Коэффициент корреляции Пирсона указывает на силу линейной связи между двумя переменными, но его значение, как правило, не полностью характеризует их взаимосвязь. В частности, если условное среднее из дано , обозначается , не является линейным в , коэффициент корреляции будет не в полной мере определить форму .
Y{\ displaystyle Y}Икс{\ displaystyle X}E(Y∣Икс){\ displaystyle \ operatorname {E} (Y \ mid X)}Икс{\ displaystyle X}E(Y∣Икс){\ displaystyle \ operatorname {E} (Y \ mid X)}
Прилегающие изображение показывает разброс участков из квартет энскомбы , набор из четырех различных пар переменных , созданный Фрэнсис Анскомбами . Четыре переменные имеют одинаковое среднее значение (7,5), дисперсию (4,12), корреляцию (0,816) и линию регрессии ( y = 3 + 0,5 x ). Однако, как видно на графиках, распределение переменных сильно отличается. Первый (вверху слева), кажется, распределен нормально и соответствует тому, что можно было бы ожидать, рассматривая две коррелированные переменные и следуя предположению о нормальности. Второй (вверху справа) не распространяется нормально; хотя можно наблюдать очевидную взаимосвязь между двумя переменными, она не является линейной. В этом случае коэффициент корреляции Пирсона не указывает на то, что существует точная функциональная связь: только степень, в которой эта связь может быть аппроксимирована линейной зависимостью. В третьем случае (внизу слева) линейная зависимость идеальна, за исключением одного выброса, который оказывает достаточное влияние, чтобы снизить коэффициент корреляции с 1 до 0,816. Наконец, четвертый пример (внизу справа) показывает другой пример, когда одного выброса достаточно для получения высокого коэффициента корреляции, даже если связь между двумя переменными не является линейной.
у{\ displaystyle y}
Эти примеры показывают, что коэффициент корреляции как сводная статистика не может заменить визуальный анализ данных. Иногда говорят, что примеры демонстрируют, что корреляция Пирсона предполагает, что данные следуют нормальному распределению , но это верно лишь отчасти. Корреляцию Пирсона можно точно рассчитать для любого распределения, имеющего конечную матрицу ковариаций , которая включает большинство распределений, встречающихся на практике. Однако коэффициент корреляции Пирсона (вместе с выборочным средним и дисперсией) является достаточной статистикой только в том случае, если данные взяты из многомерного нормального распределения. В результате коэффициент корреляции Пирсона полностью характеризует взаимосвязь между переменными тогда и только тогда, когда данные взяты из многомерного нормального распределения.
Понятие корреляции
Корреляция (от латинского «correlatio» – соотношение, взаимосвязь) – математический термин, который означает меру статистической вероятностной зависимости между случайными величинами (переменными).
Пример: возьмем два вида взаимосвязи:
- Первый – ручка в руке человека. В какую сторону движется рука, в такую сторону и ручка. Если рука находится в состоянии покоя, то и ручка не будет писать. Если человек чуть сильнее надавит на нее, то след на бумаге будет насыщеннее. Такой вид взаимосвязи отражает жесткую зависимость и не является корреляционным. Это взаимосвязь – функциональная.
- Второй вид – зависимость между уровнем образования человека и прочтением литературы. Заранее неизвестно, кто из людей больше читает: с высшим образованием или без него. Эта связь – случайная или стохастическая, ее изучает статистическая наука, которая занимается исключительно массовыми явлениями. Если статистический расчет позволит доказать корреляционную связь между уровнем образованности и прочтением литературы, то это даст возможность делать какие-либо прогнозы, предсказывать вероятностное наступление событий. В этом примере с большой долей вероятности можно утверждать, что больше читают книги люди с высшим образованием, те, кто более образован. Но поскольку связь между данными параметрами не функциональная, то мы можем и ошибиться. Всегда можно рассчитать вероятность такой ошибки, которая будет однозначно невелика и называется уровнем статистической значимости (p).
Примерами взаимосвязи между природными явлениями являются: цепочка питания в природе, организм человека, который состоит из систем органов, взаимосвязанных между собой и функционирующих как единое целое.
Каждый день мы сталкиваемся с корреляционной зависимостью в повседневной жизни: между погодой и хорошим настроением, правильной формулировкой целей и их достижением, положительным настроем и везением, ощущением счастья и финансовым благополучием. Но мы ищем связи, опираясь не на математические расчеты, а на мифы, интуицию, суеверия, досужие домыслы. Эти явления очень сложно перевести на математический язык, выразить в цифрах, измерить. Другое дело, когда мы анализируем явления, которые можно просчитать, представить в виде цифр. В таком случае мы можем определить корреляцию с помощью коэффициента корреляции (r), отражающего силу, степень, тесноту и направление корреляционной связи между случайными переменными.
Сильная корреляция между случайными величинами – свидетельство наличия некоторой статистической связи конкретно между этими явлениями, но эта связь не может переноситься на эти же явления, но для другой ситуации. Часто исследователи, получив в расчетах значительную корреляцию между двумя переменными, основываясь на простоте корреляционного анализа, делают ложные интуитивные предположения о существовании причинно-следственных взаимосвязей между признаками, забывая о том, что коэффициент корреляции носит вероятностный характер.
Пример: количество травмированных во время гололеда и число ДТП среди автотранспорта. Эти величины будут коррелировать между собой, хотя они абсолютно не взаимосвязаны между собой, а имеют только связь с общей причиной этих случайных событий – гололедицей. Если же анализ не выявил корреляционной взаимосвязи между явлениями, это еще не является свидетельством отсутствия зависимости между ними, которая может быть сложной нелинейной, не выявляющейся с помощью корреляционных расчетов.
Первым, кто ввел в научный оборот понятие корреляции, был французский палеонтолог Жорж Кювье. Он в XVIII веке вывел закон корреляции частей и органов живых организмов, благодаря которому появилась возможность восстанавливать по найденным частям тела (останкам) облик всего ископаемого существа, животного. В статистике термин корреляции впервые применил в 1886 году английский ученый Френсис Гальтон. Но он не смог вывести точную формулу для расчета коэффициента корреляции, но это сделал его студент – известнейший математик и биолог Карл Пирсон.
Анализ временной задержки
Взаимная корреляция полезна для определения временной задержки между двумя сигналами, например, для определения временных задержек для распространения акустических сигналов через решетку микрофонов. После вычисления взаимной корреляции между двумя сигналами максимум (или минимум, если сигналы имеют отрицательную корреляцию) функции взаимной корреляции указывает момент времени, когда сигналы лучше всего выровнены; то есть, задержка по времени между двумя сигналами определяется аргументом максимума, или агд макс из кросс-корреляции , как и в
- τdелаузнак равноарграмммаИкст∈р((ж⋆грамм)(т)){\ displaystyle \ tau _ {\ mathrm {delay}} = {\ underset {t \ in \ mathbb {R}} {\ operatorname {arg \, max}}} ((f \ star g) (t))}
Памятка
- Корреляция – это соотношение, взаимозависимость нескольких переменных.
- Связь бывает положительной и отрицательной.
- Коэффициент корреляции определяет степень взаимозависимости одной переменной от другой.
- На основании корреляции люди выдвигают гипотезы (часто ошибочные).
- Истинная причина корреляции порою скрыта под множеством факторов и внешних сил.
- Бывает ложная корреляционная зависимость.
- Раскладывая яйца по корзинам, помните о том, что они не должны коррелироваться друг с другом.
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
* Нажимая на кнопку «Подписаться» Вы соглашаетесь с политикой конфиденциальности.
Подборки по теме
- Вопросы и ответы
- Использую для заработка
- Полезные онлайн-сервисы
- Описание полезных программ
Использую для заработка
Корреляция и диверсификация
Как знания о корреляции активов могут помочь лучше вкладывать деньги? Думаю, вы все хорошо знакомы с золотым правилом инвестора — не клади все яйца в одну корзину. Речь, естественно, идёт о диверсификации, которая неразрывно связана с понятием корреляции. Это улавливается даже из названия — английское diversify означает «разнообразить», а как коэффициент корреляции как раз показывает схожесть или различие двух явлений.
Другими словами, инвестировать в финансовые инструменты с высокой корреляцией не очень хорошо. Почему? Все просто — похожие активы плохо диверсифицируются. Вот пример портфеля двух активов с корреляцией +1:

Как видите, график портфеля во всех деталях повторяет графики каждого из активов — рост и падение обоих активов синхронны. Диверсификация в теории должна снижать инвестиционные риски за счёт того, что убытки одного актива перекрываются за счёт прибыли другого, но здесь этого не происходит совершенно. Все показатели просто усредняются:

Портфель даёт небольшой выигрыш в снижении рисков — но только по сравнению с более доходным Активом 1. А так, никаких преимуществ по сути нет, нам лучше просто вложить все деньги в Актив 1 и не париться.
А вот пример портфеля двух активов с корреляцией близкой к 0:

Где-то графики следуют друг за другом, где-то в противоположных направлениях, какой-либо однозначной связи не наблюдается. И вот здесь диверсификация уже работает:

Мы видим заметное снижение СКО, а значит портфель будет менее волатильным и более стабильно расти. Также видим небольшое снижение максимальной просадки, особенно если сравнивать с Активом 1. Инвестиционные инструменты без корреляции достаточно часто встречаются и из них имеет смысл составлять портфель.
Впрочем, это не предел. Наиболее эффективный инвестиционный портфель можно получить, используя активы с корреляцией -1:

Уже знакомое вам «зеркало» позволяет довести показатели риска портфеля до минимальных:
Несмотря на то, что каждый из активов обладает определенным риском, портфель получился фактически безрисковым. Какая-то магия, не правда ли? Очень жаль, но на практике такого не бывает, иначе инвестирование было бы слишком лёгким занятием.
Коэффициент линейной корреляции
Ковариация неудобна тем, что имеет размерность квадрата случайных величин. Кроме того, ковариация маленькой статистической зависимости двух случайных величин с большой дисперсией (у хотя бы одной из этих
величин) получается такой же, как большая статистическая зависимость у двух других случайных величин с маленькими дисперсиями. Поэтому ковариацию удобно нормировать на среднеквадратичные отклонения.
Коэффициент корреляции, это ковариация, нормированная на среднеквадратичные отклонения двух случайных величин.
Свойства коэффициента корреляции:
- Коэффициент корреляции может принимать значения от -1 до +1. Значения -1 и +1 этот коэффициент принимает только при линейной функциональной зависимости между X и Y. Обычно, говорят, что
если коэффициент корреляции равен +1, то это абсолютно коррелирующие величины (или коррелированные на все 100%). А если коэффициент корреляции равен -1, то говорят, что это абсолютно антикоррелирующие
величины (или антикоррелированные на все 100%). - Коэффициент корреляции между независимыми случайными величинами равен нулю. Но обратное неверно! Если коэффициент корреляции двух случайных величин равен нулю, то это ещё не означает, что эти случайные
величины независимые. Они просто некоррелированные. - Линейные преобразования случайных величин X и Y не изменяют их коэффициента корреляции: ρ(x,y)=ρ(a+bx,c+dy)
Матрица коэффициентов корреляций для нескольких случайных величин X, Y, …, Z всегда симметрична, причем на главной диагонали этой матрицы всегда стоят единицы.
Положительное соотношение
Положительная корреляция – когда коэффициент корреляции больше 0 – означает, что обе переменные движутся в одном направлении. Когда ρ равно +1, это означает, что две сравниваемые переменные имеют идеальную положительную взаимосвязь; когда одна переменная движется выше или ниже, другая переменная движется в том же направлении с той же величиной.
Чем ближе значение ρ к +1, тем сильнее линейная зависимость. Например, предположим, что стоимость цен на нефть напрямую связана с ценами на авиабилеты с коэффициентом корреляции +0,95. Взаимосвязь между ценами на нефть и стоимостью авиабилетов имеет очень сильную положительную корреляцию, так как значение близко к +1. Таким образом, если цена на нефть снижается, цены на авиабилеты также уменьшаются, а если цена на нефть растет, то же самое происходит и с ценами на авиабилеты.
На приведенной ниже диаграмме мы сравниваем один из крупнейших банков США, JPMorgan Chase & Co. ( биржевым фондом Financial Select SPDR Exchange Traded Fund (ETF) (XLF ).1 Как вы понимаете, компания JPMorgan Chase & Co. должна иметь положительную корреляцию с банковской отраслью в целом. Мы видим, что коэффициент корреляции в настоящее время составляет 0,98, что свидетельствует о сильной положительной корреляции. Значение выше 0,50 обычно свидетельствует о положительной корреляции.
Понимание корреляции между двумя акциями (или одной акцией) и отраслью может помочь инвесторам оценить, как акции торгуются по сравнению с аналогами. Все типы ценных бумаг, включая облигации, сектора и ETF, можно сравнить с помощью коэффициента корреляции.
Пример применения метода корреляционного анализа
В Великобритании было предпринято любопытное исследование. Оно посвящено связи курения с раком легких, и проводилось путем корреляционного анализа. Это наблюдение представлено ниже. Исходные данные для корреляционного анализа
| Профессиональная группа | курение | смертность |
| Фермеры, лесники и рыбаки | 77 | 84 |
| Шахтеры и работники карьеров | 137 | 116 |
| Производители газа, кокса и химических веществ | 117 | 123 |
| Изготовители стекла и керамики | 94 | 128 |
| Работники печей, кузнечных, литейных и прокатных станов | 116 | 155 |
| Работники электротехники и электроники | 102 | 101 |
| Инженерные и смежные профессии | 111 | 118 |
| Деревообрабатывающие производства | 93 | 113 |
| Кожевенники | 88 | 104 |
| Текстильные рабочие | 102 | 88 |
| Изготовители рабочей одежды | 91 | 104 |
| Работники пищевой, питьевой и табачной промышленности | 104 | 129 |
| Производители бумаги и печати | 107 | 86 |
| Производители других продуктов | 112 | 96 |
| Строители | 113 | 144 |
| Художники и декораторы | 110 | 139 |
| Водители стационарных двигателей, кранов и т. д. | 125 | 113 |
| Рабочие, не включенные в другие места | 133 | 146 |
| Работники транспорта и связи | 115 | 128 |
| Складские рабочие, кладовщики, упаковщики и работники разливочных машин | 105 | 115 |
| Канцелярские работники | 87 | 79 |
| Продавцы | 91 | 85 |
| Работники службы спорта и отдыха | 100 | 120 |
| Администраторы и менеджеры | 76 | 60 |
| Профессионалы, технические работники и художники | 66 | 51 |
Начинаем корреляционный анализ. Решение лучше начинать для наглядности с графического метода, для чего построим диаграмму рассеивания (разброса).
Она демонстрирует прямую связь. Однако на основании только графического метода сделать однозначный вывод сложно. Поэтому продолжим выполнять корреляционный анализ. Пример расчета коэффициента корреляции представлен ниже.
С помощью программных средств (на примере MS Excel будет описано далее) определяем коэффициент корреляции, который составляет 0,716, что означает сильную связь между исследуемыми параметрами. Определим статистическую достоверность полученного значения по соответствующей таблице, для чего нам нужно вычесть из 25 пар значений 2, в результате чего получим 23 и по этой строке в таблице найдем r критическое для p=0,01 (поскольку это медицинские данные, здесь используется более строгая зависимость, в остальных случаях достаточно p=0,05), которое составляет 0,51 для данного корреляционного анализа. Пример продемонстрировал, что r расчетное больше r критического, значение коэффициента корреляции считается статистически достоверным.
3) уравнение линейной регрессии на
Это и есть та самая оптимальная прямая , которая проходит максимально близко ко всем точкам. Обычно её находят методом наименьших квадратов, и мы пойдём знакомым путём
Заполним расчётную таблицу:
Обратите внимание, что в отличие от задач урока МНК у нас появился дополнительный столбец , он потребуется в дальнейшем, для расчёта коэффициента корреляции
Сократим оба уравнения на 2, всё попроще будет:
Систему решим по формулам Крамера: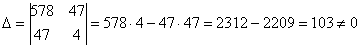 , значит, система имеет единственное решение.
, значит, система имеет единственное решение.

Таким образом, искомое уравнение регрессии:
Данное уравнение показывает, что с увеличением количества прогулов («икс») на 1 единицу суммарная успеваемость падает в среднем на 6,0485 – примерно на 6 баллов. Об этом нам рассказал коэффициент «а»
И обратите особое внимание, что эта функция возвращает нам средние (среднеожидаемые) значения «игрек» для различных значений «икс»
Почему это регрессия именно « на » и о происхождении самого термина «регрессия» я рассказал чуть ранее, в параграфе . Если кратко, то полученные с помощью уравнения средние значения успеваемости («игреки») регрессивно возвращают нас к первопричине – количеству прогулов. Вообще, регрессия – не слишком позитивное слово, но какое уж есть.
Найдём пару удобных точек для построения прямой: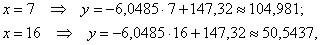
отметим их на чертеже (малиновый цвет) и проведём линию регрессии: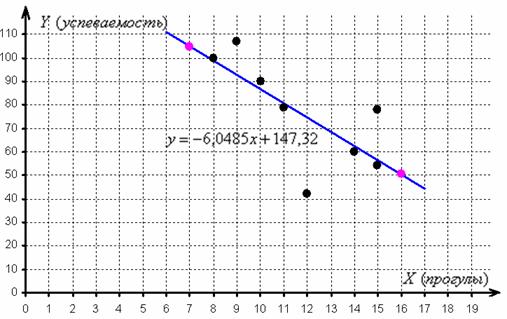
Говорят, что уравнение регрессии аппроксимирует (приближает) эмпирические данные (точки), и с помощью него можно интерполировать (восстановить) неизвестные промежуточные значения, так при количестве прогулов среднеожидаемая успеваемость составит балла.
И, конечно, осуществимо прогнозирование, так при среднеожидаемая успеваемость составит баллов. Единственное, нежелательно брать «иксы», которые расположены слишком далеко от эмпирических точек, поскольку прогноз, скорее всего, не будет соответствовать действительности. Например, при значение может вообще оказаться невозможным, ибо у успеваемости есть свой фиксированный «потолок». И, разумеется, «икс» или «игрек» в нашей задаче не могут быть отрицательными.
Второй вопрос касается тесноты зависимости. Очевидно, что чем ближе эмпирические точки к прямой, тем теснее линейная корреляционная зависимость – тем уравнение регрессии достовернее отражает ситуацию, и тем качественнее полученная модель. И наоборот, если многие точки разбросаны вдали от прямой, то признак зависит от вовсе не линейно (если вообще зависит) и линейная функция плохо отражает реальную картину.
Прояснить данный вопрос нам поможет:
Терминология в обработке изображений
Нулевой нормализованной взаимной корреляции (ZNCC)
Для приложений обработки изображений, в которых яркость изображения и шаблона может изменяться в зависимости от условий освещения и экспозиции, изображения могут быть сначала нормализованы. Обычно это делается на каждом этапе путем вычитания среднего и деления на стандартное отклонение . То есть взаимная корреляция шаблона с частичным изображением
т(Икс,у){\ Displaystyle т (х, у)}ж(Икс,у){\ Displaystyle f (х, у)}
- 1п∑Икс,у1σжσт(ж(Икс,у)-μж)(т(Икс,у)-μт){\ displaystyle {\ frac {1} {n}} \ sum _ {x, y} {\ frac {1} {\ sigma _ {f} \ sigma _ {t}}} \ left (f (x, y ) — \ mu _ {f} \ right) \ left (t (x, y) — \ mu _ {t} \ right)}.
где это количество пикселей в и ,
является средним и это стандартное отклонение от .
п{\ displaystyle n}т(Икс,у){\ Displaystyle т (х, у)}ж(Икс,у){\ Displaystyle f (х, у)}μж{\ displaystyle \ mu _ {f}}ж{\ displaystyle f}σж{\ displaystyle \ sigma _ {f}}ж{\ displaystyle f}
В терминах функционального анализа это можно рассматривать как скалярное произведение двух нормализованных векторов . То есть, если
- F(Икс,у)знак равнож(Икс,у)-μж{\ Displaystyle F (x, y) = f (x, y) — \ mu _ {f}}
а также
- Т(Икс,у)знак равнот(Икс,у)-μт{\ Displaystyle Т (х, у) = т (х, у) — \ му _ {т}}
тогда указанная сумма равна
- ⟨F‖F‖,Т‖Т‖⟩{\ displaystyle \ left \ langle {\ frac {F} {\ | F \ |}}, {\ frac {T} {\ | T \ |}} \ right \ rangle}
где — внутренний продукт, а — норма L ² . Затем Коши-Шварц подразумевает, что ZNCC имеет диапазон .
⟨⋅,⋅⟩{\ Displaystyle \ langle \ cdot, \ cdot \ rangle}‖⋅‖{\ Displaystyle \ | \ cdot \ |}-1,1{\ displaystyle }
Таким образом, если и являются действительными матрицами, их нормализованная взаимная корреляция равна косинусу угла между единичными векторами и , будучи, таким образом, тогда и только тогда, когда равно умноженному на положительный скаляр.
ж{\ displaystyle f}т{\ displaystyle t}F{\ displaystyle F}Т{\ displaystyle T}1{\ displaystyle 1}F{\ displaystyle F}Т{\ displaystyle T}
Нормализованная корреляция — это один из методов, используемых для сопоставления шаблонов , процесса, используемого для поиска совпадений шаблона или объекта в изображении. Это также двумерная версия коэффициента корреляции момента произведения Пирсона .
Нормализованная взаимная корреляция (NCC)
NCC похож на ZNCC с той лишь разницей, что не вычитает локальное среднее значение интенсивности:
- 1п∑Икс,у1σжσтж(Икс,у)т(Икс,у){\ displaystyle {\ frac {1} {n}} \ sum _ {x, y} {\ frac {1} {\ sigma _ {f} \ sigma _ {t}}} f (x, y) t ( х, у)}
Коэффициенты ранговой корреляции
Коэффициенты ранговой корреляции , такие как коэффициент ранговой корреляции Спирмена и коэффициент ранговой корреляции (τ) Кендалла, измеряют степень, в которой по мере увеличения одной переменной другая переменная имеет тенденцию увеличиваться, не требуя, чтобы это увеличение было представлено линейной зависимостью. Если по мере увеличения одной переменной другая уменьшается , коэффициенты ранговой корреляции будут отрицательными. Эти коэффициенты ранговой корреляции принято рассматривать как альтернативу коэффициенту Пирсона, который используется либо для уменьшения объема вычислений, либо для того, чтобы сделать коэффициент менее чувствительным к ненормальности в распределениях. Однако у этого взгляда мало математического обоснования, поскольку коэффициенты ранговой корреляции измеряют другой тип взаимосвязи, чем коэффициент корреляции продукта-момента Пирсона , и лучше всего рассматриваются как меры другого типа ассоциации, а не как альтернативный показатель совокупности. коэффициент корреляции.
Чтобы проиллюстрировать природу ранговой корреляции и ее отличие от линейной корреляции, рассмотрим следующие четыре пары чисел :
(Икс,у){\ Displaystyle (х, у)}
- (0, 1), (10, 100), (101, 500), (102, 2000).
По мере того, как мы переходим от каждой пары к следующей, она увеличивается, и то же самое . Это соотношение является совершенным, в том смысле , что увеличение будет всегда сопровождается увеличением . Это означает, что у нас есть идеальная ранговая корреляция, и коэффициенты корреляции Спирмена и Кендалла равны 1, тогда как в этом примере коэффициент корреляции продукта-момента Пирсона равен 0,7544, что указывает на то, что точки далеко не лежат на прямой линии. Таким же образом, если всегда уменьшается при увеличении , коэффициенты ранговой корреляции будут равны -1, в то время как коэффициент корреляции момента произведения Пирсона может быть или не может быть близок к -1, в зависимости от того, насколько близки точки к прямой линии. Хотя в крайних случаях идеальной ранговой корреляции оба коэффициента равны (оба +1 или оба -1), это обычно не так, и поэтому значения двух коэффициентов не могут быть осмысленно сравнены. Например, для трех пар (1, 1) (2, 3) (3, 2) коэффициент Спирмена равен 1/2, а коэффициент Кендалла — 1/3.
Икс{\ displaystyle x}у{\ displaystyle y}Икс{\ displaystyle x}у{\ displaystyle y}у{\ displaystyle y}Икс{\ displaystyle x}
Примеры
Необходимо определить взаимосвязь двух переменных: уровня интеллектуального развития (по данным проведенного тестирования) и количества опозданий за месяц (по данным записей в учебном журнале) у школьников.
Исходные данные представлены в таблице:
|
№ |
Данные по уровню IQ (x) |
Данные по количеству опозданий (y) |
|
1 |
100 |
6 |
|
2 |
115 |
2 |
|
3 |
117 |
1 |
|
4 |
119 |
1 |
|
5 |
134 |
2 |
|
6 |
94 |
8 |
|
7 |
105 |
3 |
|
8 |
103 |
4 |
|
9 |
111 |
3 |
|
10 |
124 |
|
|
Сумма |
1122 |
30 |
|
Среднее арифметическое |
112,2 |
3 |
Чтобы дать правильную интерпретацию полученному показателю, необходимо проанализировать знак коэффициента корреляции (+ или -) и его абсолютное значение (по модулю).
В соответствии с таблицей классификации коэффициента корреляции по силе делаем вывод о том, rxy = -0,827 – это сильная отрицательная корреляционная зависимость. Таким образом, количество опозданий школьников имеет очень сильную зависимость от их уровня интеллектуального развития. Можно сказать, что ученики с высоким уровнем IQ опаздывают реже на занятия, чем ученики с низким IQ.
Важно! Принято считать, что чем r ближе по модулю к 1, тем ближе связь между анализируемыми переменными к линейной. Если величина r близка к -1, то связь обратная (c возрастанием переменной х переменная у убывает).. Коэффициент корреляции может применяться как учеными для подтверждения или опровержения предположения о зависимости двух величин или явлений и измерения ее силы, значимости, так и студентами для проведения эмпирических и статистических исследований по различным предметам
Необходимо помнить, что этот показатель не является идеальным инструментом, он рассчитывается лишь для измерения силы линейной зависимости и будет всегда вероятностной величиной, которая имеет определенную погрешность
Коэффициент корреляции может применяться как учеными для подтверждения или опровержения предположения о зависимости двух величин или явлений и измерения ее силы, значимости, так и студентами для проведения эмпирических и статистических исследований по различным предметам. Необходимо помнить, что этот показатель не является идеальным инструментом, он рассчитывается лишь для измерения силы линейной зависимости и будет всегда вероятностной величиной, которая имеет определенную погрешность.
Корреляционный анализ применяется в следующих областях:
- экономическая наука;
- астрофизика;
- социальные науки (социология, психология, педагогика);
- агрохимия;
- металловедение;
- промышленность (для контроля качества);
- гидробиология;
- биометрия и т.д.
Причины популярности метода корреляционного анализа:
- Относительная простота расчета коэффициентов корреляции, для этого не нужно специальное математическое образование.
- Позволяет рассчитать взаимосвязи между массовыми случайными величинами, которые являются предметом анализа статистической науки. В связи с этим этот метод получил широкое распространение в области статистических исследований.
Надеюсь, теперь вы сможете отличить функциональную взаимосвязь от корреляционной и будете знать, что когда вы слышите по телевидению или читаете в прессе о корреляции, то под ней подразумевают положительную и достаточно значимую взаимозависимость между двумя явлениями.

